This post aims to define a general purpose data processing architecture to run experiments, the idea is to have a modular system to test new tools and learn how to best take advantage of them.
Also, this is something focused on my own learning and attempt to document, and share if useful, anything that I come across.
That being said, here are the initial diagram for the architecture, this is something that most likely will be evolving rapidly and add much more detail to, but at this point the below image capture the essence of what I want to build.
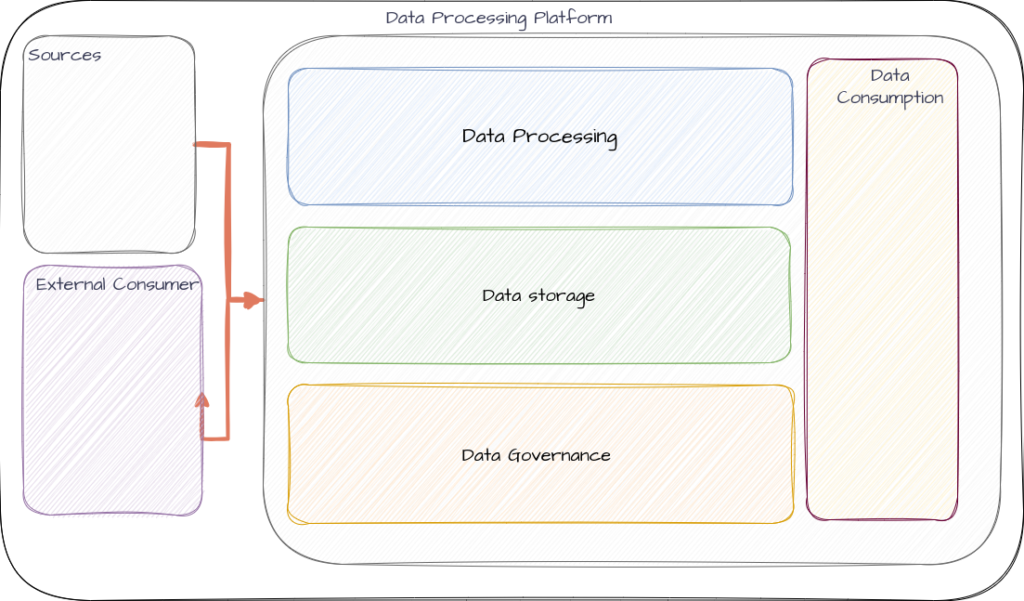
The initial focus will be to identify tools for each block and see how to implement them. Hopefully with the help of docker this architecture should be modular enough to be able to change the different parts of it with not much trouble.
One thing to mention, is that I haven’t figured out just yet the sources and targets, but most likely will be aiming to some sort of streaming (sensor, API, Etc) and batch I’ll try to find a dataset of good size, but that big that collapses my development machine.
The rest of the boxes goes as follows:
- Data Processing – Tools to process Stream, batch and realtime data. Also tools and processes to move things around (Dev/UAT/Prod environments) and enable development of data processing routines.
- Data Storage – How to persist data and make it available, what tools to use and feature set of each. Also, how to manage data lifecycle in an efficient way.
- Data Governance – Lineage, metadata, quality, semantic layer, and observability. Tools and processes to make this complex subject work.
- Data Consumption – How to make use of the data once it is ready.
In the next post, I’ll start with the first box, data governance. Define what governance is, what pieces will help me to get it done, and what pieces are missing.
