
This blog post is for the Udacity DS Nanodegree Capstone project. Below you’ll find the analysis and ML model results. Also, in the following link you’ll find all the code associated with this blog post.
Problem introduction.
Based on the dataset provided by Starbucks, the aim is to provide a way to identify the best profiles/offers to be sent in order to obtain the best response. Below the details as shared by Starbucks:
Introduction
This data set contains simulated data that mimics customer behavior on the Starbucks rewards mobile app. Once every few days, Starbucks sends out an offer to users of the mobile app. An offer can be merely an advertisement for a drink or an actual offer such as a discount or BOGO (buy one get one free). Some users might not receive any offer during certain weeks.
Not all users receive the same offer, and that is the challenge to solve with this data set.
Your task is to combine transaction, demographic and offer data to determine which demographic groups respond best to which offer type. This data set is a simplified version of the real Starbucks app because the underlying simulator only has one product whereas Starbucks actually sells dozens of products.
Every offer has a validity period before the offer expires. As an example, a BOGO offer might be valid for only 5 days. You’ll see in the data set that informational offers have a validity period even though these ads are merely providing information about a product; for example, if an informational offer has 7 days of validity, you can assume the customer is feeling the influence of the offer for 7 days after receiving the advertisement.
You’ll be given transactional data showing user purchases made on the app including the timestamp of purchase and the amount of money spent on a purchase. This transactional data also has a record for each offer that a user receives as well as a record for when a user actually views the offer. There are also records for when a user completes an offer.
Keep in mind as well that someone using the app might make a purchase through the app without having received an offer or seen an offer.
Example
To give an example, a user could receive a discount offer buy 10 dollars get 2 off on Monday. The offer is valid for 10 days from receipt. If the customer accumulates at least 10 dollars in purchases during the validity period, the customer completes the offer.
However, there are a few things to watch out for in this data set. Customers do not opt into the offers that they receive; in other words, a user can receive an offer, never actually view the offer, and still complete the offer. For example, a user might receive the “buy 10 dollars get 2 dollars off offer”, but the user never opens the offer during the 10 day validity period. The customer spends 15 dollars during those ten days. There will be an offer completion record in the data set; however, the customer was not influenced by the offer because the customer never viewed the offer.
With these, We are set to try to answer these questions:
- How does my population looks like.
- What profile is more likely to complete an offer.
- What are the offers that draws more attention
The project contains 3 dataset to be analyzed:
- portfolio.json – containing offer ids and meta data about each offer (duration, type, etc.)
- profile.json – demographic data for each customer
- transcript.json – records for transactions, offers received, offers viewed, and offers completed
Here is the schema and explanation of each variable in the files:
portfolio.json
- id (string) – offer id
- offer_type (string) – type of offer ie BOGO, discount, informational
- difficulty (int) – minimum required spend to complete an offer
- reward (int) – reward given for completing an offer
- duration (int) – time for offer to be open, in days
- channels (list of strings)
profile.json
- age (int) – age of the customer
- became_member_on (int) – date when customer created an app account
- gender (str) – gender of the customer (note some entries contain ‘O’ for other rather than M or F)
- id (str) – customer id
- income (float) – customer’s income
transcript.json
- event (str) – record description (ie transaction, offer received, offer viewed, etc.)
- person (str) – customer id
- time (int) – time in hours since start of test. The data begins at time t=0
- value – (dict of strings) – either an offer id or transaction amount depending on the record
Now, having clear objective and knowing the datasets to be used, let’s dive into the following tasks:
- Understand the basics of the data
- Clean and prepare data for further analysis and ML models
- Complete analysis
- ML model.
Strategy to solve the problem.
As mentioned in the last section, we want to understand the datasets beyond the initial description, and also we want to be able to provide ML models to provide recommendations based on new data, for this we will follow the below steps.
- Understand data as is to identify cleaning/preparation steps.
- Apply cleaning routine in order to have data ready for analysis and also clean it up for the Machine Learning Models.
- This will require to convert data from a transactional form into a wide form and dummy variable creation.
- Build and exploratory analysis and derive insights from the data.
- Train a couple of Machine Learning models for recommendations
- Tune the hyperparameter of the models by using Grid Search
- Train and evaluate the models to find the best perfomer.
With that, we should have a solid path to recommend who should receive offers.
Metrics
In order to evaluate the models we will use F1 score, as it represent the harmonic mean between Accuracy and Recall, more information can be found in this link
EDA-Understanding and cleaning the data
We will start by reviewing the profiles dataset:
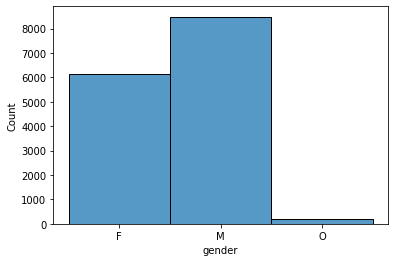
Mostly male present in the dataset with a 57% of representation, one important point is that there is also 13% NaN values, so in order to solve that we extracted the representation of each value and fill the missing based on that distribution:


After applying the fill function the representation for each value looks still very similar.
We also looked at the income for the profiles to understand how it was distributed, some clean was necessary to account for the missing values, but in this case we use the mean to produce the final chart.
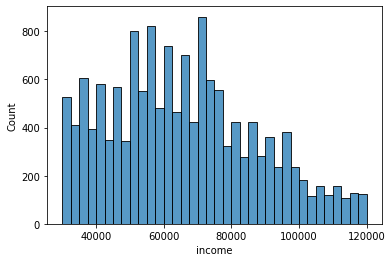
The peak is around 75K with a decline in the tail of the distribution.
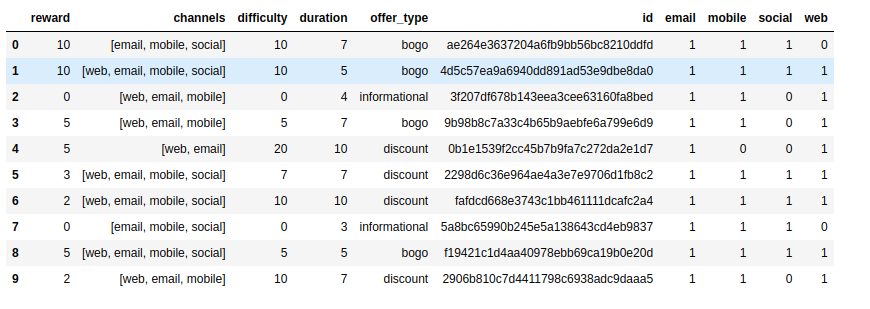
The portfolio dataset is mostly a dimension with not much analysis to be done, but some preparation is needed, in this case we transformed the channel column into dummies to the following dataset:
Next the transcript dataset has little space for direct analysis, but after the full clean-up, it will be one of the main inputs for the ML model. some insights from the file on the following charts.
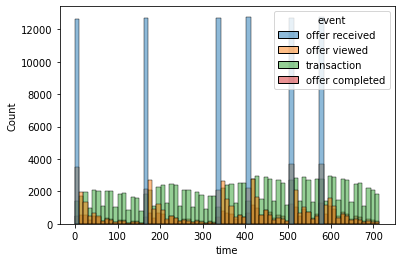
So, couple of insights from the chart:
- Transaction are spread evenly after the offer has been received.
- Views tend to fade quickly after an offer has been received.
- Need further review to analyze the completion
Further data cleaning and preparation.
The main focus will be to get transcript into shape, for that we will follow these steps:
Assumptions before cleaning:
- Offer time windows ends when new one starts (Event=offer received)
- All events within that timeframe can be allocated to the specific offer
- Offer may not complete.
- Offer may not be viewed but completed.
Tasks on cleaning:
- Order by Person and Time
- Assign Offer ID to all records within Offer time Window
- Expand values to new columns
- Flatten based on Person and Offer ID
- Will need to sum based on Person and Offer ID
- Add count of transactions based on Person and Offer ID
- Add Flag for viewed
- Add Flag for completed
- Combine with portfolio and profile
For the details on these steps, you can check the github project, the final dataset looks something like this:
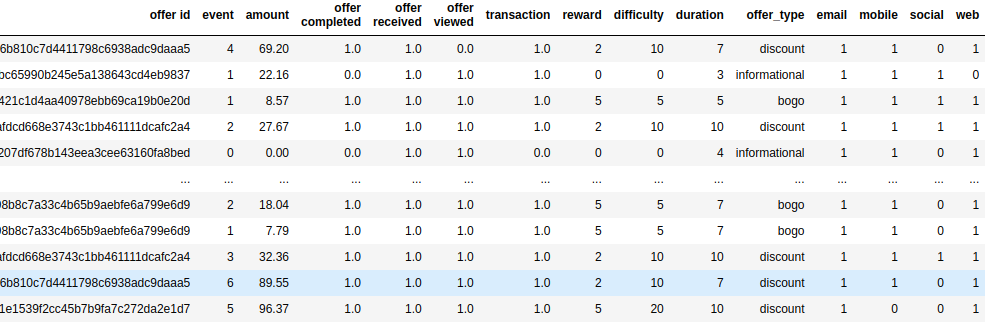
With this, we can start the final analysis on the data.
Analysis.
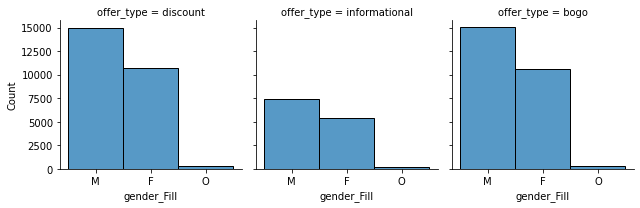
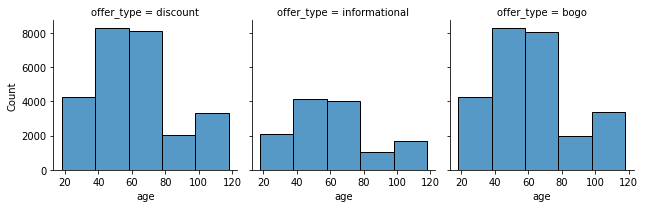
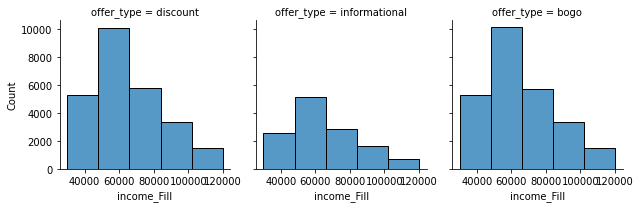
What we can extract from the above charts is:
- Gender Wise offers follows the distribution from profile for the different types of offers, being M the most represented group.
- For age there is clear concentration between 40 and 80 years for all offer type
- For income there is a clear focus on the 45K to 70K bins in terms of all offers.
Let’s review more in detail to understand the response
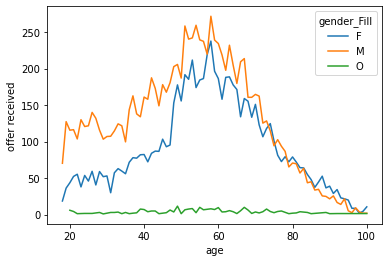
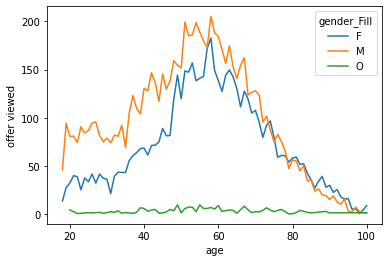
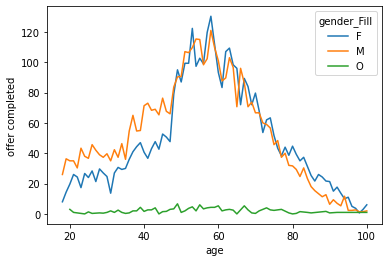
Age is not that relevant as expected, the spike around 60 is still present, but in general there is no other pattern.
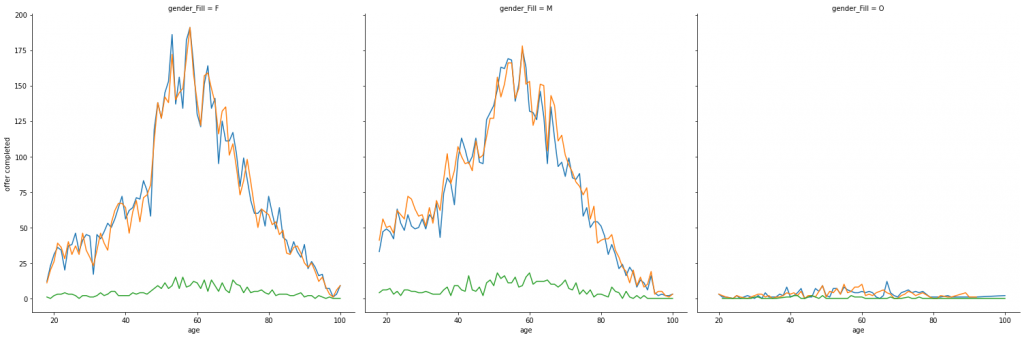
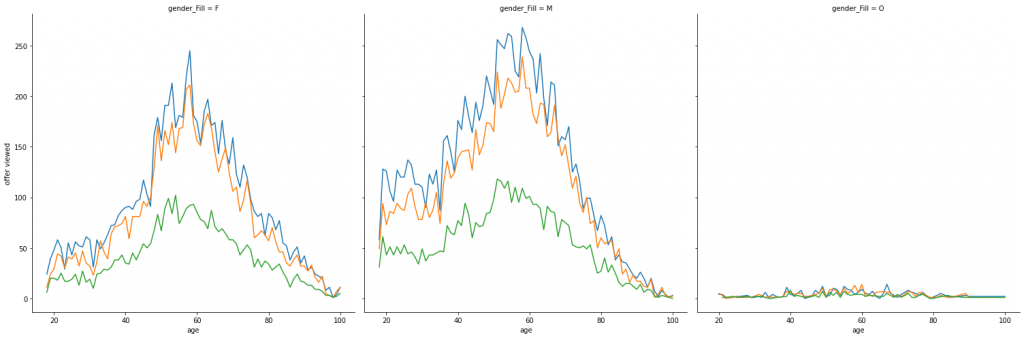
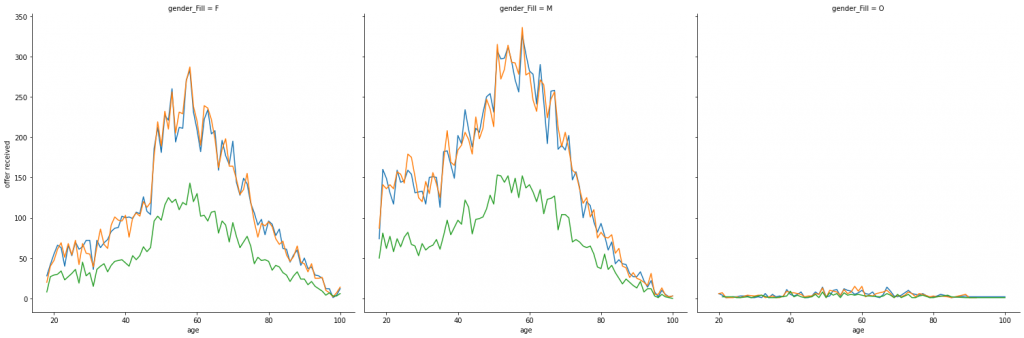
We can see, again, that higher rates on response is on the 60 brackets.
After some more filtering and review to better understand how the population reacts to the offers we have the following tables for the profiles that actually viewed and completed the offers
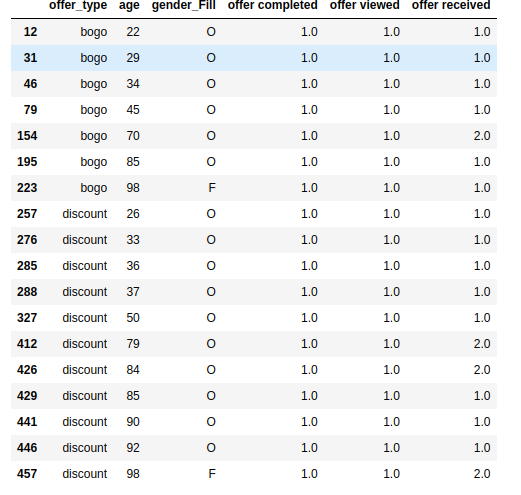
Independent of the age Gender=O is the group most likely to view and respond to offers.
Machine Learning model – Modeling
With the dataset in shape, we went ahead and tested 3 different ML models
- AdaBoostClassifier
- RandonForestClassifier
- LogisticRegression
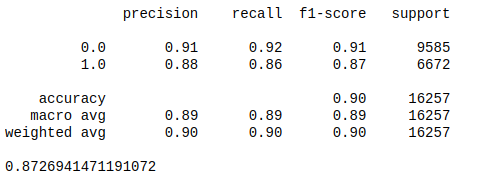
The details on these three models can be found on the github, but bellow we will see the summary of the training and validation for each one.
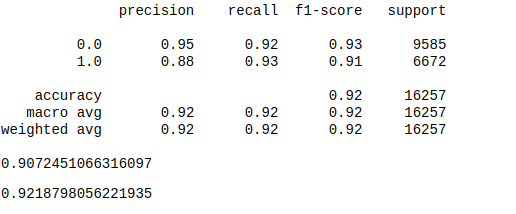
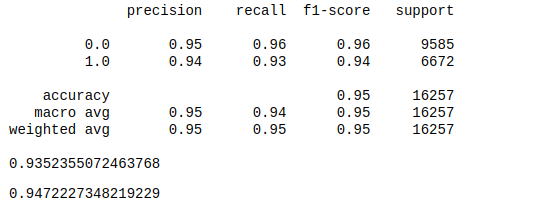
Hyperparameter Tunning
After training, we apply a grid search to find the best parameters for the LogisticRegrestion and the RandomForest models. below the configuration for both grid search execution, first the logistic regression:

The execution took around an hour due to the high number of combinations and after identifying the optimal parameters we got the following results:
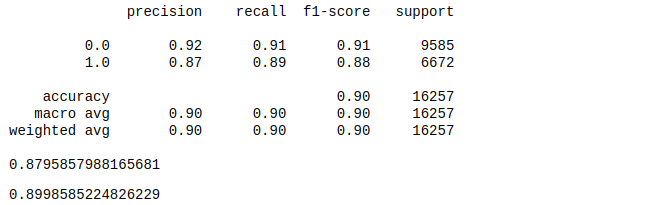
We can see that there is no much improvement with the change on the parameters.
The same process was executed for RandomForestModel with the following configuration:

This was an extremely lengthy process taking multiple hours to complete, and after that, the improvement was small:
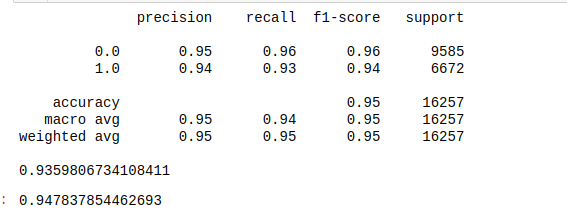
Concluding that the RandonForest model is the best performer, but considering the time necessary to execute this check, may not be a good option-
Results
The results for the projects are two-fold:
- An exploratory analysis – this analysis suggest that there is a clear target group that will respond as expected to the offers, this means once they view the offer they will fullfill the confiditions
- In this area there is still space for improvements with more in depth analysis and if more data can be used to better understand, for instance the impact of informational.
- Also with access to data in real team offers can be made more personalized in order to target groups of customes more accuarate.
- Model creation – After a lot of data cleaning, Dataset where in shape to test multiple models: Randonforest, Logistic Regression and AdaBoost, the last one did not move forward due to low results.
- Logistic regression performed a decent job(0.8726 F1) and improve almost nothing after applying the optimal parameters provided by Grid Search (0.8789 F1)
- Random Forest performed better on initial run (0.9352 F1) and improved slightly after Grid Search (0.9359 F1), this model was the best performer Random Forest model was cross validated with a 94.7% Accuracy and 0.003 standard deviation
The best performer model, the RandonFores was also validated using cross-validation as mentioned above to make sure the model is robust enough to perform as expected on new data.
Conclusion and further improvements.
We started the project trying to answer three questions, and while reviewing the data, doing the needed clean-up and visualizing, the questions were possible to answer with a decent level of detail.
From the project in general data cleaning was challenging specially on the transcript file to get it into wide form. Other than that, the other files were very straightforward to deal with and prepare them for the analysis and ML models.
One aspect that is open for improvement is the usage of Deep Learning models on a more complete dataset in terms of the features of the profiles, with more data and a Deep Learning algorithm, better recommendations can be made. Also, a web app would be very beneficial to both, get recommendations and analyze transcript real time-data.
The Notebook that goes with this post can be found in: GitHub
